
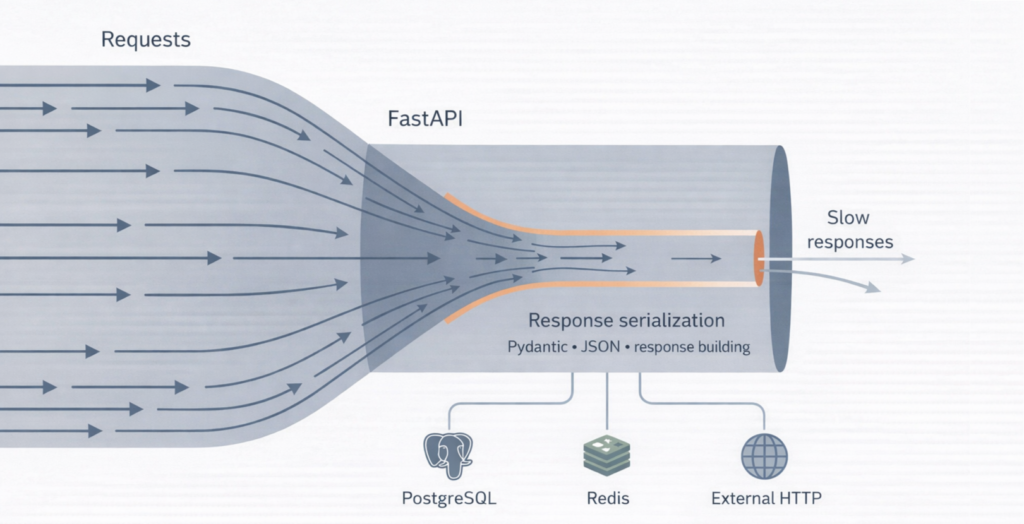
People pick FastAPI for speed and async support. But on one of our projects, an API handling only ~150 RPS started responding in 3–5 seconds. Sometimes requests even timed out.
Infrastructure looked fine:
- CPU sat around 35–40%
- PostgreSQL showed no slow queries
- the network didn’t look guilty either
Everything looked “normal”, yet users were waiting seconds for a response. Here’s what was going on.
Service architecture
The stack was pretty standard:
- FastAPI
- PostgreSQL
- SQLAlchemy 2.0 (async)
- Redis
- Docker + Kubernetes
- Uvicorn + Gunicorn
One of the endpoints (simplified) looked like this:
@router.get("/orders/{order_id}")
async def get_order(order_id: int, db: AsyncSession = Depends(get_db)):
order = await order_service.get_order(order_id, db)
return orderInside the handler we did three things:
- a query to PostgreSQL
- a request to Redis
- an HTTP call to an external service
All of it was async. So, in theory, it should have been fast.
Symptoms under load
The degradation pattern was very telling:
When latency grows in steps like this while the database stays quiet, two things are usually worth checking first:
- a CPU bottleneck somewhere that doesn’t show up clearly in aggregate metrics
- a chokepoint in the event loop that turns the service into a queue
Profiling
We ran py-spy:
py-spy top --pid <pid>And got an unexpected breakdown:
- ~40% in
json.dumps - ~30% in Pydantic serialization
- ~20% in SQLAlchemy result processing
The event loop was spending a significant amount of time building and serializing the response – not talking to the database and not waiting on the network.
Problem #1: Pydantic overhead
The endpoint returned a large object:
class OrderResponse(BaseModel):
id: int
items: list[Item]
customer: CustomerSome orders had 200+ items. So each request effectively did:
It’s convenient, validated, and clean. But it’s also expensive – especially when responses are large and request volume is high.
Problem #2: classic N+1 in SQLAlchemy
The second issue was even more basic.
order = await session.get(Order, order_id)
items = order.itemsItems were loaded lazily. If an order had 200 items, it was easy to end up with 200 extra SQL queries.
On a single request you might not notice it. Under load, though, the math gets ugly very quickly.
What was actually happening per request
In practice, each HTTP request looked roughly like this:
- 1 query for Order
- up to 200 queries for Items
- creation of hundreds of Pydantic objects
- JSON serialization
In tests it “seems to work”. In production under load, it turns into a queue, and latency shoots into seconds.
What we changed
1. Removed N+1 with eager loading
We switched relationship loading to selectinload:
stmt = (
select(Order)
.options(selectinload(Order.items))
.where(Order.id == order_id)
)
result = await session.execute(stmt)
order = result.scalar_one()After that the query pattern became:
- 1 query for Order
- 1 query for Items
This alone took a lot of pressure off the service.
2. Reduced Pydantic overhead where it made sense
Before:
return OrderResponse.model_validate(order)After:
return {
"id": order.id,
"items": [{"id": i.id, "price": i.price} for i in order.items],
}Latency dropped by almost 2x in our case.
We didn’t remove Pydantic completely. We kept it where it’s genuinely useful – at system boundaries, for validating incoming data, and in places where a strict schema matters. But we stopped running large nested objects through it end-to-end when there was no real benefit.
3. Switched to a faster JSON encoder: orjson
We added ORJSONResponse:
from fastapi.responses import ORJSONResponse
app = FastAPI(default_response_class=ORJSONResponse)On large responses the gain was very noticeable – roughly 3–5x faster on the serialization step in our case. The exact number depends on the data shape, but the change was far from cosmetic.
4. Parallelized external HTTP calls
Before, external requests were executed sequentially:
data1 = await client.get(url1)
data2 = await client.get(url2)
data3 = await client.get(url3)We changed that to parallel execution:
data1, data2, data3 = await asyncio.gather(
client.get(url1),
client.get(url2),
client.get(url3),
)If those calls are independent, this can significantly reduce total response time.
Results after the fixes
The service started handling 3–4x more load.
Takeaways
- Async doesn’t automatically mean fast. It helps with waiting on I/O, but it won’t save you from heavy serialization and extra CPU work.
- N+1 can stay invisible for a long time. At low load the code may look perfectly fine. Under real traffic it can turn into a serious bottleneck very quickly.
- Large responses are expensive. The bigger the payload, the more you pay for serialization, validation, and data transformation.
- Profile first, optimize second. Otherwise it’s easy to spend time improving the wrong part of the system.
What to check if your FastAPI service suddenly gets slow
- any blocking code:
requests, synchronous clients, or heavy CPU-bound Python work - N+1 queries in your ORM usage
- how much time goes into Pydantic serialization
- which JSON encoder you’re using
- whether workers, timeouts, and server limits are configured appropriately
Conclusion
Sometimes the problem isn’t the database. Sometimes it isn’t the network. Sometimes it isn’t even the external services.
Sometimes it all comes down to how you build and serialize the response. And in Python services, that’s one of the most common – and most annoying – production surprises.


